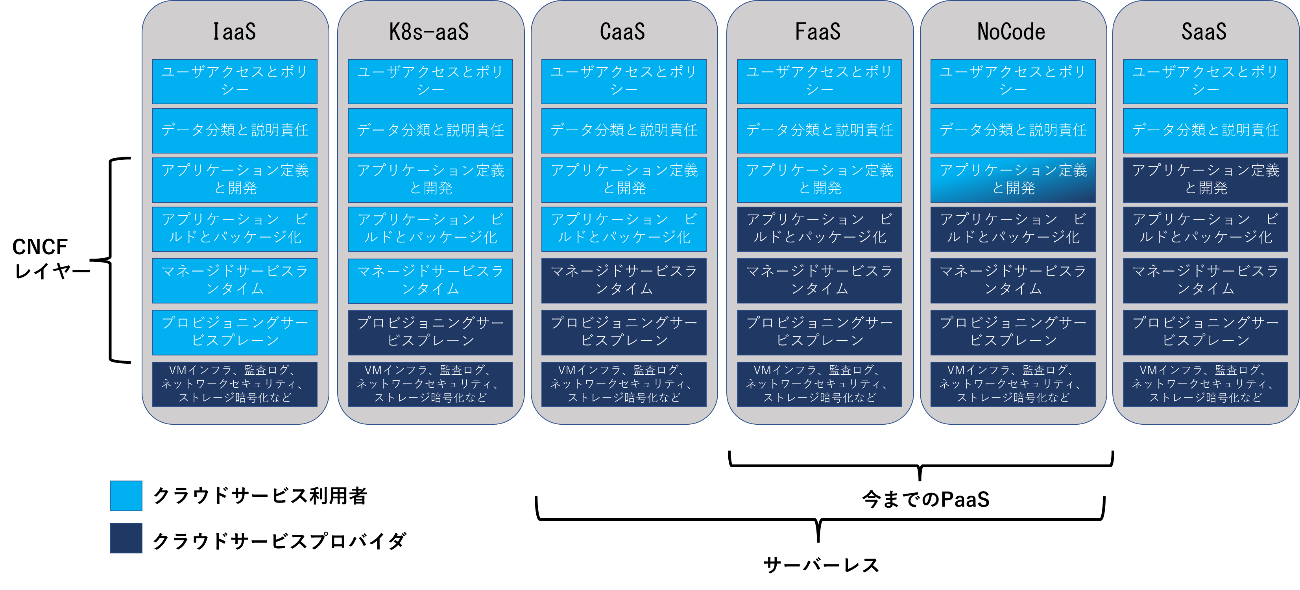
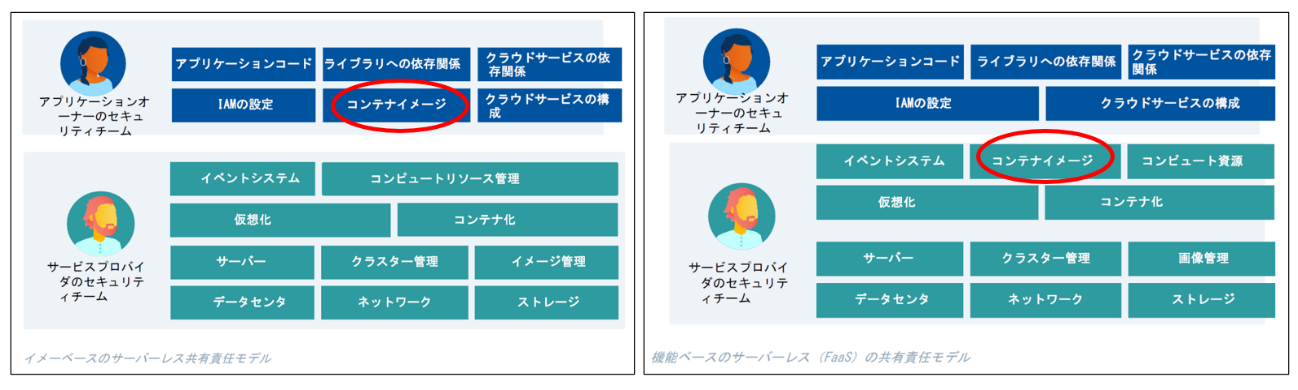
ゲノムデータベース利活用のエコシステムでは、産官学の様々な組織・コミュニティの専門家がアクセスし、共同作業を行う形態が多く見られる。そこで大きな課題となるのがアクセス制御に代表されるアンデンティティ/アクセス管理である。
CSAガイダンスからみたアンデンティティ/アクセス管理
はじめに、クラウドセキュリティアライアンス(CSA)が2011年11月に公開した「クラウドコンピューティングのためのセキュリティガイダンス V3.0」(https://www.cloudsecurityalliance.jp/j-docs/csaguide.v3.0.1_J.pdf)では、 「第12章 アイデンティティ、権限付与、アクセス管理」において、以下のような内容で概説している。
12.1 この文書で使用する用語
12.2 クラウド環境におけるアイデンティティ序論
12.3 クラウド用のアイデンティティアーキテクチャ
12.4 アイデンティティ連携
12.5 アイデンティティと属性のプロビジョニングとガバナンス
12.6 権限付与プロセス
12.7 承認とアクセス管理
12.8 アイデンティティと属性の提供者とインタフェースするためのアーキテクチャ
12.9 アイデンティティと属性の信頼レベル
12.10 クラウドシステム上のアカウントプロビジョニング
12.11 Identity-as-a-Service
12.12 コンプライアンスと監査 (IDaaS)
12.13 アイデンティティのためのアプリケーション設計
12.14 アイデンティティとデータ保護
12.15 利用者化とアイデンティティの挑戦
12.16 アイデンティティサービス提供者
12.17 推奨事項
次に、CSAが2017年7月26日に公開した「クラウドコンピューティングのための
セキュリティガイダンス v4.0」(https://cloudsecurityalliance.jp/j-docs/CSA_Guidance_V4.0_J_V1.1_20180724.pdf)では、「DOMAIN 12 アイデンティティ管理、権限付与管理、アクセス管理」において、以下のような内容で概説している。
12.0 はじめに
12.0.1 クラウドにおけるIAMの違いは何か
12.1 概要
12.1.1 クラウドコンピューティングにおけるIAM標準
12.1.2 クラウドコンピューティングのためのユーザ、アイデンティティ管理
12.1.3 認証と資格情報
12.1.4 権限付与管理とアクセス管理
12.1.5 特権ユーザ管理
12.2 推奨事項
- CSAガイダンス v4.0では、以下のような、アイデンティティ管理、権限付与管理、アクセス管理の推奨事項を提示している。
- 組織は、クラウドサービスでアイデンティティと認可を管理するための包括的かつ公式な計画とプロセスを開発する必要がある。
- 外部のクラウド事業者に接続する場合は、可能であれば ID 連携を使用して、既存のアイデンティティ管理を拡張する。内部のアイデンティティに結びついていないクラウドプロバイダ固有のアイデンティティ管理を最小限に抑えるようにする。
- 適切であれば 、アイデンティティブローカの使用を検討する。
- クラウド利用者は、アイデンティティプロバイダを管理しアイデンティティと属性を定義する責任を負う。
- これらは権威のあるルートソースに基づくべきである。
- オンプレミスのディレクトリサーバが利用できないあるいは要件を満たしていない場合、分散した組織ではクラウドホスト型のディレクトリサーバの使用を検討する必要がある。
- クラウド利用者は、すべての外部のクラウドアカウントに対して多要素認証(MFA)を選択し、認証連携を使用する場合にはMFAステータスを属性として送信するべきである。
- 特権を持つアイデンティティは、常にMFAを使用することが望ましい。
- クラウド事業者とプロジェクト毎に、メタ構造や管理プレーンへのアクセスに重点をおいた権限付与マトリクスを開発すること。
- クラウド事業者またはプラットフォームでサポートされている場合は、権限付与マトリクスを技術ポリシーに組み入れること。
- クラウドコンピューティングではロールベースアクセス制御(RBAC)より属性ベースアクセス制御(ABAC)を優先すること 。
- クラウド事業者は、オープンな標準に基づく内部アイデンティティと ID連携の両方を提供する必要がある。
- 魔法のプロトコルはない。まず、ユースケースを取り上げて制約条件を洗い出し、次に適切なプロトコルを見つけること 。
米国防総省の調達基準としての多層防御型ICAM戦略
他方、アクセス制御に関連して米国防総省(DoD)は、2020年3月30日、「アイデンティティ・資格情報・アクセス管理(ICAM)戦略」(https://dodcio.defense.gov/Portals/0/Documents/Cyber/ICAM_Strategy.pdf)を策定している。
この中で国防総省は、イデンティティ・資格情報・アクセス管理(ICAM)について、デジタルアイデンティティの生成および関連する属性の維持に関連する幅広い範囲の活動であり、人間/人間以外の主体向けの資格情報の発行、資格情報を利用した認証、認証されたアイデンティティおよび関連する属性に基づくアクセス管理制御に係る意思決定だとしている。その上で、以下のようなICAM戦略の目標を掲げている。
・目標1: データ中心のアプローチを実装して、アイデンティティおよびその他の属性を収集、検証、維持、共有する
- 目標1.1: 収集時の属性データを検証するための標準規格を設定して、属性データの正確性を維持し、すべてのローカルデータレポジトリの改ざんに対して属性値を保護する
- 目標1.2: 属性データの共有に関する意思決定をする際に、データレポジトリを利用するためのプロセスやサービスレベルアグリーメント(SLAs)の言語を設定する
- 目標1.3: 信頼されるレポジトリへの書込みアクセス向けの標準規格を設定する
・目標2: 共通の標準規格、共有サービス、連携を通して、DoDネットワークおよびリソースへの認証を向上し、可能なものにする
- 目標2.1: アプリケーションオーナーが、DoDおよび外部の資格情報を活用して、DoDネットワークやリソースにアクセスするためのリスクベースのガイドラインを開発・維持する
- 目標2.2: DoD従業員、外部委託先、退職者、扶養家族など、すべてのタイプのユーザおよびすべての環境向けに資格情報を提供するケーパビリティを実装する
- 目標2.3: クラウドサービスをサポートするためのICMケーパビリティを実装する
- 目標2.4: DoDネットワークの境界で、連携した外部信用情報を介して、米国政府、米国以外の政府、商用パートナーなど、認証されたミッションパートナー向けの共有サービスを実装する
・目標3: 共有サービスを実装して、エンタープライズICAMの導入を促進する
- 目標3.1: 法律、規制、ポリシー、ミッション、リソースへのアクセスを統治するローカルの要求事項を統合するデジタルポリシーフレームワークを設定する
- 目標3.2: DoDリソースへのアクセスのためのコアのデジタルポリシールールを実装するために必要な属性および値を設定する
- 目標3.3: DoD内部およびミッションパートナーとの間双方で属性を交換するためのシンタックスおよびセマンティックを定義する
- 目標3.4: 属性交換、デジタルポリシー管理、ポリシー意思決定など、プロビジョニング自動化・動的アクセス制御を導入するために、エンタープライズ共有サービスを実装する
・目標4:インサイダー脅威および外部攻撃を検知するために、一貫したモニタリングとロギングを可能にする
- 目標4.1: 情報リソース、ミッション、データに対するアクセス、特権、リスクの評価および考慮をサポートするために、DoDマスタユーザレコードを設定し、進化させる
- 目標4.2: 認可データを提供して、特別なインシデント、不適切な認可、行動異常の周りで協働するための監査体制を認める
- 目標4.3: 現代化した監査のケーパビリティに対するICAMインフラストラクチャのサポートを進化させる
- 目標4.4: ミッションパートナーとともに、協働型監査をサポートする
・目標5:エンタープライズICAMソリューションの開発・採用を促進するために、ガバナンス構造を強化する
- 目標5.1: エンタープライズICAMソリューションの定義・実装に関するDoD CIOやUSCCと、サービスおよび政府機関の責任を定義する
- 目標5.2: サービスおよび政府機関のステークホルダー間のコミュニケーションや協力関係を促進するために、統合プログラムチーム(IPT)を構築する
- 目標5.3: コアのジョブ機能としてICAMを促進するために、トレーニングおよびパフォーマンス管理を特定する
- 目標5.4: 現行のICAM関連活動の実装・維持への支出に関するエンタープライズ全体の見積を策定する
・目標6:アイデンティフィケーション、資格証明、認証、認可のライフサイクル管理向けの要求事項を明確に定義するために、DoDポリシーおよび標準規格を構築する
- 目標6.1: 外部発行の資格情報との相互運用性など、リスクのレベルおよび環境的な制約上、適切な資格証明技術の利用をサポートするために、既存のDoDポリシーをアップデートする
- 目標6.2: 情報システムが 資格証明、認証、認可向けのDoDエンタープライズソリューションの利用をサポートすることを実現するために必要なDoDポリシーを構築する
- 目標6.3: 連携、相互運用性、資格証明、認証、認可、予期せぬユーザ向けサポートに関する国防総省全体の技術標準規格を定義し、維持する
- 目標6.4: データへのアクセスを許可するために、属性やデジタルポリシールールを活用する際に、リスク管理および責任のためのDoDポリシーを構築する
- 目標6.5: すべての情報システム向けの調達プロセスへのICAM標準規格の強制を取り入れる
- 目標6.6: エンタープライズICAMの達成に向けて、進歩を実証・追跡するメトリクスを特定し、収集する
・目標7: ミッションの目標を実行するというDoDコンポーネントのニーズと、DoDリソースを確保するというDoDエンタープライズのニーズをサポートするために、ICAM活動の実行と進化を維持する
- 目標7.1: ミッションの目標をサポートするICAMケーパビリティの統合を保証するために、DoDエンタープライズICAMサービスの実装を調整する
- 目標7.2: ミッションの目標を達成し、特定された要求事項を優先順位付けし、適切な実装向けエンタープライズサービスと要求事項を調整するために、DoDコンポーネントが必要とするICAM関連要求事項を収集し、関係づけるようなプロセスを設定し、維持する
- 目標7.3: 継続的な改善手法をICAMエンタープライズサービスに取り入れることによって、技術進歩を取り入れるとともに、進化するDoDコンポーネントのミッションの要求事項に取組むために、維持モードにおけるサービスを評価して改善できるようにする
- 目標7.4: ICAM関連プロセスおよび技術: ICAM関連プロセスおよび技術を専門とするサイバー労働力の開発・維持に投資する
- 目標7.5: 作戦保全(OPSEC)を、ICAM関連活動の計画策定、実行、評価に統合する
国防総省は、ICAM戦略を調達基準の一部と位置づけて、属性ベースアクセス制御(ABAC)に必要な基盤構築や、マルチステークホルダーエコシステムを前提とする監査対応準備など、多層防御的なソリューションを積極的に実装・運用している。
ICAM実装支援のための参照設計書を開発・提供
ICAM戦略を受けて、国防総省CIO室(DoD CIO)は、2020年6月に「DoDエンタープライズのアイデンティティ・資格情報・アクセス管理(ICAM)参照設計」(https://dodcio.defense.gov/Portals/0/Documents/Cyber/DoD_Enterprise_ICAM_Reference_Design.pdf) を策定している。本参照設計書では、以下のような目的を掲げている。
- ミッションのオーナーが、ミッションパートナーによる認可されたアクセスの実現など、ミッションのニーズを満たせるように、ICAM要求事項を理解し、現状および計画におけるDoDエンタープライズICAMサービスを記述することによって、ICAM実装に関する意思決定を可能にするよう支援する
- DoDエンタープライズICAMサービスのオーナーやオペレーターが、これらのサービスを有効に相互作用させてICAMケーパビリティをサポートできるよう支援する
- DoDエンタープライズサービスがミッションのニーズを満たさない場合、DoDコンポーネントが、DoDエンタープライズICAMサービスを利用する方法や、DoDコンポーネント、COIまたはローカルレベルのICAMサービスを運用する方法を理解する際にサポートする
その上で、本参照設計書は、以下のような構成になっている。
(DISA=国防情報システムセンター、DMDC=国防マンパワーデータセンター、NSA=国家安全保障局)
1.イントロダクション
- 1.1目的
- 1.2適用
- 1.3 DoDコミュニティ
- 1.3.1. DoD内部コミュニティ
- 1.3.2. 外部ミッションパートナー・コミュニティ
- 1.3.3. 受益者
- 1.3.4. 他の主体
- 1.4 DoDの計算処理環境
- 1.5参考文献
- ICAMケーパビリティの概要
- 2.1 トランスフォーメーションの目標
- 2.2 ICAMケーパビリティ分類の概要(DoDAF CV-2)
- 2.2.1. コアICAMケーパビリティ
- 2.2.1.1 アイデンティティ管理
- 2.2.1.2 資格情報管理
- 2.2.1.3 アクセス管理
- 2.2.2. アクセス説明責任ケーパビリティ
- 2.2.2.1 ログ収集と集約
- 2.2.2.2 アクセスのレビュー
- 2.2.2.3 アイデンティティの解決
- 2.2.3. コンタクトデータ・ケーパビリティ
- 2.2.3.1 コンタクトデータの収集
- 2.2.3.2 コンタクトデータ・ロックアップ
- 2.3 DoDエンタープライズICAMサービスの利用
- 2.3.1. DoDエンタープライズICAMサービスの利用からのDoDエンタープライズのベネフィット
- 2.3.2 DoDエンタープライズICAMサービスの利用からの情報システムのベネフィット
- 2.3.3 DoDエンタープライズICAMサービスの利用に対する課題の低減
- ICAMデータフロー
- 3.1 コアICAMケーパビリティ
- 3.1.1. アイデンティティ管理
- 3.1.1.1 人間主体
- 3.1.1.2 人間以外の主体(NPE)
- 3.1.1.3 連携主体
- 3.1.2. 資格情報管理
- 3.1.2.1 内部資格情報管理
- 3.1.2.2 外部資格情報登録
- 3.1.3. アクセス管理
- 3.1.3.1 リソースアクセス管理
- 3.1.3.2 プロビジョニング
- 3.1.3.3 認証
- 3.1.3.4 認可
- 3.2 アクセス説明責任ケーパビリティ
- 3.2.1. ログの収集と集約
- 3.2.2. アクセスのレビュー
- 3.2.3. アイデンティティの解決
- 3.3 コンタクトデータ・ケーパビリティ
- ICAMパターンと関連するユースケース
- 4.1 アイデンティティと資格情報のパターン
- 4.1.1. 非機密エンタープライズDoDの内部初期登録
- 4.1.2. 非機密エンタープライズミッションパートナー主体の登録
- 4.1.3. 利害関係ユーザコミュニティの登録
- 4.1.4. 利害関係人間主体アイデンティティプロバイダの登録
- 4.1.5. DoDおよび連邦政府機関向け機密エンタープライズ登録
- 4.1.6. 連邦政府機関以外のミッションパートナー主体向けの機密エンタープライズ登録
- 4.1.7. 短期の人間以外の主体(NPE)の登録
- 4.1.8. DoD受益者の登録
- 4.1.9. DoD応募者の登録
- 4.2 アクセス管理のパターン
- 4.2.1. DoD管理下のリソースへのアクセス
- 4.2.2. 予期せぬ主体向けのアクセス
- 4.2.3. 特権ユーザアクセス
- 4.2.4. ゼロトラスト
- 4.2.5. Software as a Service (SaaS)クラウドマネージドシステムへのアクセス
- 4.3 アクセス説明責任のパターン
- 4.3.1. ロギングとモニタリング
- 4.3.2. アクセスのレビュー
- 4.3.3. アイデンティティの解決
- 4.4 コンタクトデータ・ルックアップ
- DoDエンタープライズICAMサービス
- 5.1 DoD ICAMエンタープライズサービスの概要
- 5.2 プロダクションDoD ICAMエンタープライズサービス
- 5.2.1. 個人データレポジトリ(PDR) (*DMDCが運用)
- 5.2.2. アイデンティティ解決サービス(*DMDCが運用)
- 5.2.3. トラステッド・アソシエイト・スポンサー・プログラム(TASS) (*DMDCが運用)
- 5.2.4. DoD公開鍵インフラストラクチャ(PKI)(*DISAとNSAが運用)
- 5.2.5 リアルタイムの自動本人確認システム(RAPIDS) (*DMDCが運用)
- 5.2.6. 非機密インターネットプロトコルルータ(NIPRNet)エンタープライズ代替トークンシステム(NEATS)/代替トークン発行管理システム(ATIMS) (*DMDCが運用)
- 5.2.7. Purebred (*DISAが運用)
- 5.2.8. DoDセルフサービス(DS)ログオン(*DMDCが運用)
- 5.2.9. エンタープライズアイデンティティ属性サービス(EIAS) (*DMDCが運用)
- 5.2.10. アイデンティティ同期サービス(IdSS)(*DMDCが運用)
- 5.2.11. milConnect(*DMDCが運用)
- 5.2.12. エンタープライズディレクトリサービス(EDS)(*DISAとDMDCが運用)
- 5.2.13. グローバルディレクトリサービス(GDS)(*DISAが運用)
- 5.3 計画されたDoD ICAMエンタープライズサービス
- 5.3.1. ミッションパートナー登録(MPR)(*DMDCが開発中)
- 5.3.2. アイデンティティプロバイダ(IdP)(*DISAが開発中)
- 5.3.3. 多要素認証(MFA)登録サービス(*DMDCが開発中)
- 5.3.4. EIAS(強化型)
- 5.3.5. バックエンド属性交換(BAE) (*DMDCが運用)
- 5.3.6. DSログイン(強化型)
- 5.3.7. 自動アカウントプロビジョニング(AAP) (*DISAが開発中)
- 5.3.8. マスタユーザレコード(MUR) (*DISAが開発中)
- ICAM実装責任
- 6.1 DoD ICAM共同プログラム統合室(JPIO)の責任
- 6.2 DoD ICAMサービスプロバイダの責任
- 6.3 DoDコンポーネントの責任
- 6.3.1. DoDコンポーネントレベルのICAMガバナンス
- 6.3.2. DoDエンタープライズICAMサービスのサポート
- 6.3.3. DoDエンタープライズICAMサービスの利用
- 6.3.4. COIとローカルICAMサービスの運用
- 6.4 外部連携ICAMサービスプロバイダに関連する責任
- ICAMサービスギャップの概要
上記からわかるように、国防総省は、様々なアイデンティティ/アクセス管理関連サービスを開発・運用している。複数サービスが並列する中で、関与する各ステークホルダーの組織的責任体制を明確化しており、国防総省関連のバイオ技術・バイオ製造プロジェクトにおける外部委託先となるユーザ企業にとって参考になる点も多い。
加えて国防総省は、2021年7月29日、「国防総省(DoD)クラウドネイティブ・アクセスポイント(CNAP)参照設計(RD)第1.0版」(https://dodcio.defense.gov/Portals/0/Documents/Library/CNAP_RefDesign_v1.0.pdf)を策定している。CNAPは、ゼロトラストアーキテクチャ(ZTA)を活用して、どこでも、いつでも、どのデバイスからも、認可されたDoDユーザやエンドポイントによる、商用クラウド環境内のDoDリソースへの安全な認可されたアクセスを提供することを目的としている。
この参照設計書は、CNAP内部における一連のケーパビリティ、基盤コンポーネント、データフローを記述し、定義することを目的としている。本書は、CNAPを実装、接続、運用するための論理的設計パターンおよび派生的な参照実装を提供するものであり、戦闘軍司令官、軍事機関、国防情報システム局(DISA)およびその他の国防機関、商用クラウドおよび政府クラウドにおいてDoDリソースへのアクセスを必要とするミッションパートナーを対象としている。
内容
- 1.1. 目的
- 1.2. スコープ
- 1.3. 対象読者
- 1.4. ハイレベルのユーザストーリー
- 想定と原則
- 2.1 想定
- 2.2 原則
- ケーパビリティの概要
- 3.1. CNAPケーパビリティ分類の概要(DoDAF CV-2)
- 3.2. コアCNAPケーパビリティ
- C.1 – 認証・認可された主体
- C.2 – 認証されたIngress
- C.3 – 認可されたEgress
- C.4 – セキュリティのモニタリングとコンプライアンスの強制
- 3.2.4.1 モニタリングと救済策
- 3.2.4.2 コンプライアンス監査と強制
- 3.2.4.3 CSSP/DCOによる統合型可視性
- 3.2.4.4 継続的な運用認可(cATO)
- データフロー
- 4.1. CSPポータルアクセス
- 4.2. SaaSアクセス
- 4.3. 認可されたIngress
- 4.4. 認可されたEgress
- 4.5. セキュリティのモニタリングとコンプライアンスの強制
- 論理的設計パターン
- 5.1. ミッションオーナー(MO)のクラウドエンクレイブへのアクセス
- 5.2. SaaSサービスへのアクセス
- 実装責任
- 6.1. DoDエンタープライズの責任
- 6.2. ミッションオーナー(MO)の責任
- 6.3. ミッションパートナー
- 6.4. クラウドサービスプロバイダ(CSP)の責任
- 参考文献
- 附表A – 頭字語
- 附表B – 用語集
- 附表C – 推奨されるポリシーのアップデート
なお、CSAのゼロトラストリサーチ・ワーキンググループでは、ZTワークストリーム・アイデンティティ(ZT3)が、「IAM向けのゼロトラスト原則とガイダンス」を作成中であり、近日中に公開予定である(https://cloudsecurityalliance.org/artifacts/zero-trust-principles-and-guidance-for-iam/)。この作成作業においても、国防総省の各種ドキュメントが参照されている。これに先立ちCSAでは、「ゼロトラストアーキテクチャにおける医療機器」(https://www.cloudsecurityalliance.jp/site/wp-content/uploads/2023/05/Medical-Devices-In-A-Zero-Trust-Architecture_050423-J.pdf)を公開している。
米国の場合、連邦政府機関のみならず、大規模な医療施設や教育・研究機関においても、ゼロトラストアーキテクチャの実装に向けた動きが活発化している。ゼロトラストアーキテクチャは、アクセス制御と密接に関わっており、この領域での新たなソリューション開発に対する期待が高まりつつある。
CSAジャパン関西支部メンバー
健康医療情報管理ユーザーワーキンググループリーダー
笹原英司